今回の報告は下記3点について。
- モデル評価の方法確立:モデルの是非を数値化した。
- input_shape値の選択:重要なハイパーパラメーターの変更。
- 特徴量の増量と絞り込み:MACD,RSI,ボリンジャーバンドなどのオシレーター指標を特徴量に加えて変化を見る。
モデル評価系には予測価格と価格の上昇率の2つについて平方二乗誤差MSE, 絶対誤差平均MAEを出力、また1時間先が上がっているか、下がっているかの2択の正解率を出力することで評価することとした。
input_shapeは予測にどこまで過去の価格変動をさかのぼるかを指定する値。これまでは1しか試してこなかったのを、ほかの数値で比較し、モデル評価の指標を表形式で出力できるようコードを書いた。
特徴量選択では、Ta-libというPythonのライブラリを使用して、OHLCVデータから計算できるすべての特徴量(150くらい?)を取得し、相関が強すぎるもの同士を除く処理をして103個まで絞った。
結論としては、予測精度が52%台まで上がったが、まだまだである。
検討の詳細を以下にまとめる。
これまでの課題と戦略の確認
予測ロジックを再確認した。ひとつ前の価格を使って次の1時間を予測するモデル。
- 1時間前までの過去のビットコイン価格データを使って予測モデルを作る
- 新しい一時間足が確定したら終値と、それにより新たに計算できる特徴量を取得する
- 2を使用して1時間先のビットコイン価格を予測する
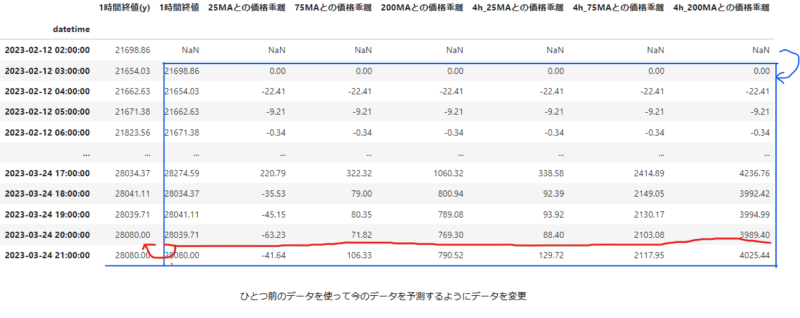
また、移動平均の値が前のデータを使用することから、データフレームの最初の方が値がおかしくなっていることに気付いた。そのため最初の100行を削除、その分取得データを増やすことにした。計900時間
このデータフレームを使用して新たに予測した。結果が以下の通り。拡大して、予測ができているのかを確認したところ、1本先を予測したいのに、予測は見事外れている。
与えられた正解を追いかけるように価格が上下しているだけのように見える。1時間ずれが生じている、いわゆるラグモデル。1時間後の価格が上がるか下がるかを予測するには使えない。
モデル評価の方法確立
前回までのモデルがダメだったのはわかったが、良いモデルの構築に向け、いいモデル、ダメなモデルを数値化する必要があった。評価に用いた指標はわかりやすさ重視で以下の5つにした。
1,2と3,4はほぼ同じ
- テストデータの、予測価格から算出した平方二乗誤差MSE
- テストデータの、予測価格から算出した絶対誤差平均MAE
- テストデータの、価格の上昇率から算出した平方二乗誤差MSE, 絶対誤差平均MAE
- テストデータの、価格の上昇率から算出した絶対誤差平均MAE
- テストデータで1時間先が上がっているか、下がっているかの2択の正解率
上記3-5を下のようなデータフレームにした。予測と実際の値で、上昇率の符号が一致すれば正解を1、不正解を0として正解率を算出。

input_shape値の選択
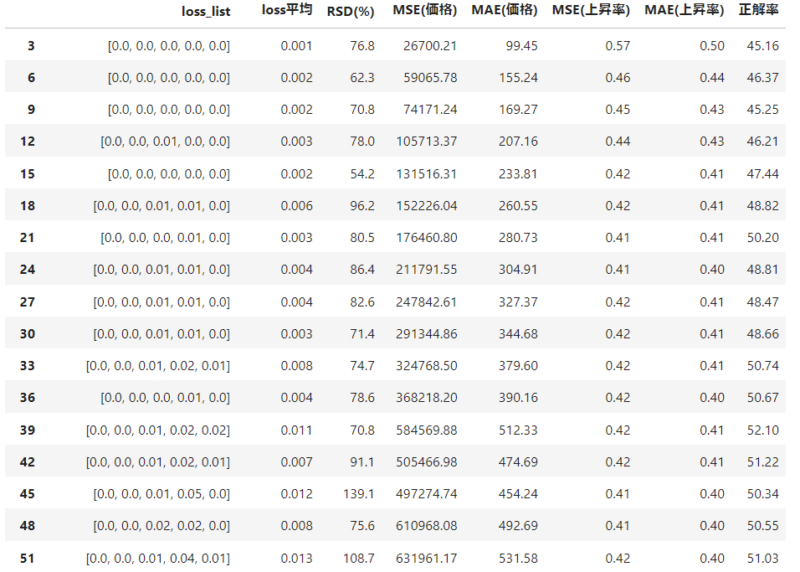
input_shapeは予測にどこまで過去の価格変動をさかのぼるかを指定する値で、重要なパラメーター。これまでは1しか試してこなかったのを、ほかの数値で比較し、モデル評価の指標を表形式で出力できるようコードを書いた。
input_shape値を引数にして、モデル評価指標を出力する関数を作り、下のように網羅的に調べることができるようになった。この例では、正解率が最大で52%に達しているものもあった。
特徴量の増量と絞り込み
最後に特徴量を補強した。MACD,RSI,ボリンジャーバンドなどのオシレーター指標を特徴量に加えた。
特徴量の計算はTa-libというPythonのライブラリを使用した。Ta-libを使うと、150程度の特徴量を取得できる。ただし、特徴量を並べてみるとわかるが、似ているものが多かったり、これ関係ある?というものも多いため、選別は必要であった。
特徴量を増やすことで足かせにならないように、”特徴量同士の相関係数が高いものを減らす”ことを目指した。特徴量同士の相関が高すぎると予測結果に悪影響を与えることが知られているためである。(多重共線性)
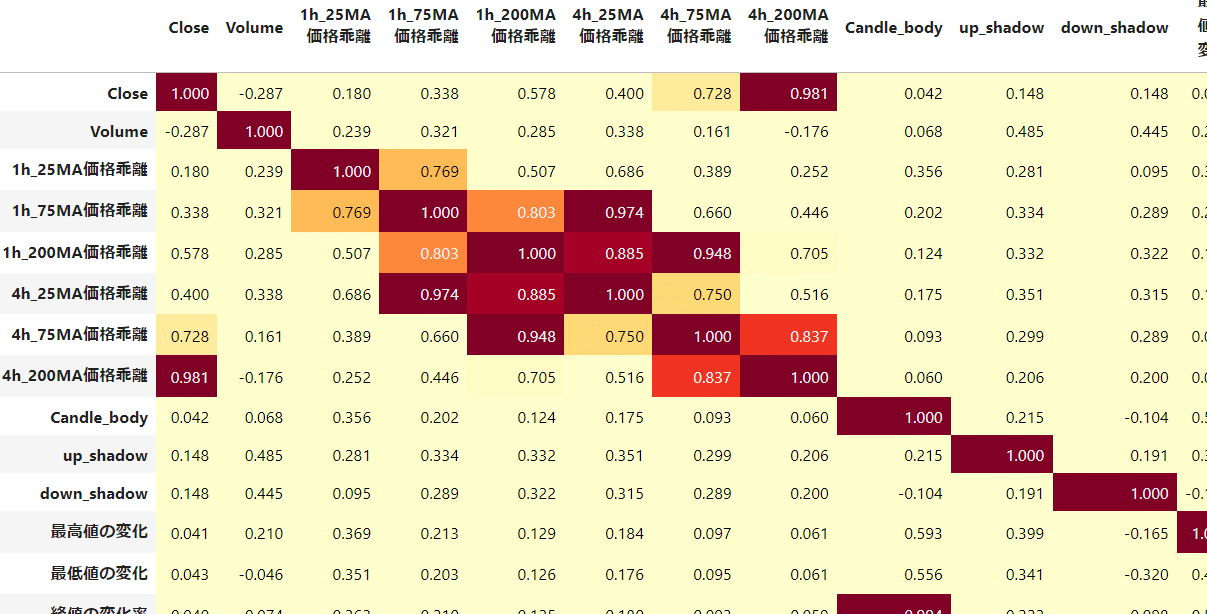
そこで、取得したすべての特徴量について、特徴量同士の相関係数を表示することにした。下の表では相関係数が0.7, 0.9を区切りに3つのグループに色分けした。
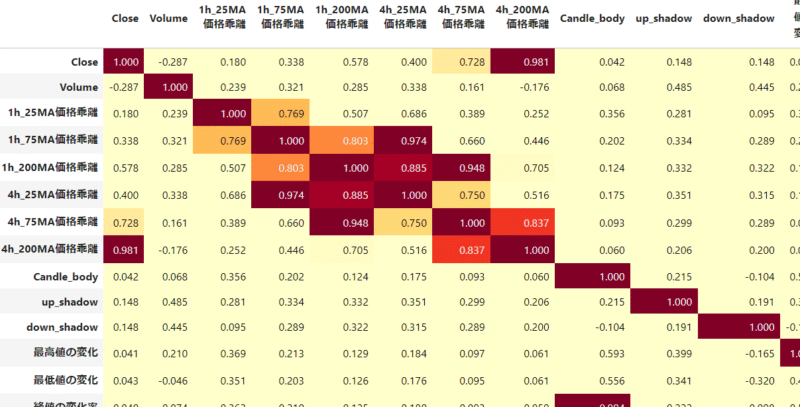
この表を見つつ、相関係数が0.9以上の特徴量をすべてチェックしていくことにした。数が多すぎたので、意味が分からなくても相関係数に問題なければ、特徴量として導入することにした。このような手順で、特徴量を103まで絞り込んだ。

なお、価格に強く影響を受ける値(終値、始値、高値、安値、移動平均線、ボリンジャーバンドなどなど)は終値との差をとるなどして表を作り直した。
次の検討項目
今回得られた評価方法と、新たに追加した特徴量をもとに予測モデルを作る。
ラグモデルにならない、予測モデルを作ることができるのか?
コメント