前回に引き続き、RNN, LSTMを用いて、ビットコイン価格の予測モデル構築を目指した。これまで予測精度がだめだめだったが、検討することでましなモデルにはなった。
これまでの課題
BinanceAPIを使って、1分ごとに、600時間分のビットコイン価格を取得し、5分足の25MA、75MA、200MA、取引量の4つを予測モデル構築に使った。
学習した600時間分のデータをわたして改めてビットコイン価格を予測させたところ、予測はだめだめだった。ここまでが先週の話(下図黄色)
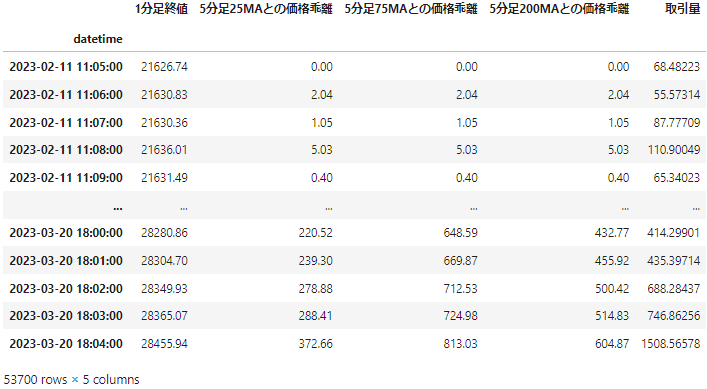
改善点として思い浮かんだのは以下2点。今回は簡単に試せる1番目のほうを試した。
- サンプリング数を減らす。1分に1回を1時間に1回、4時間に1回
- input_shape値(特徴量に、いくつ前までのビットコイン価格を加えるか)を変える。時系列データでは特徴量に加えて、予測対象の過去の値も特徴量とする。これまではinput_shape=1
今回の作業
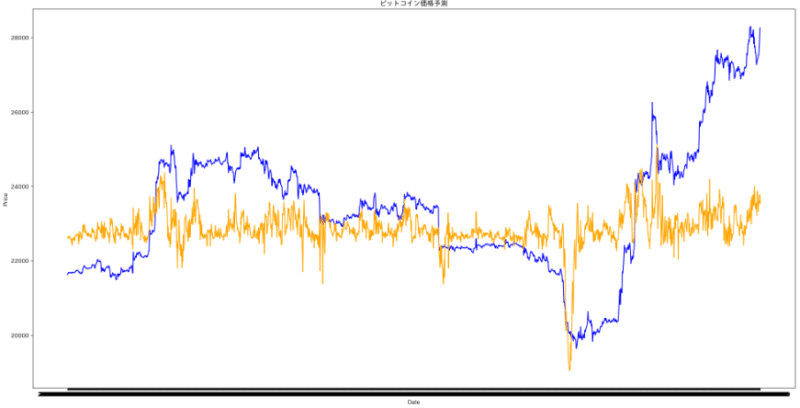
サンプリング数を1時間に1回にして、それ以外は同じ条件を試した。結果が下図。多少良くなった。
訓練データとテストデータの誤差が、下の通り。5セット行い、loss平均0.23, RSD72%

予測に使ったデータ、時間帯
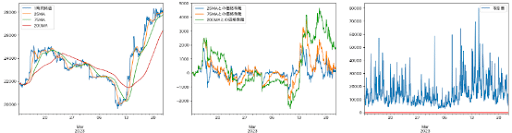
さらに1h足で取得したデータフレームを使って、1つ飛ばし=2時間に1サンプリング(左)、3つ飛ばし=4時間に1サンプリング(左)試したが改善せず。
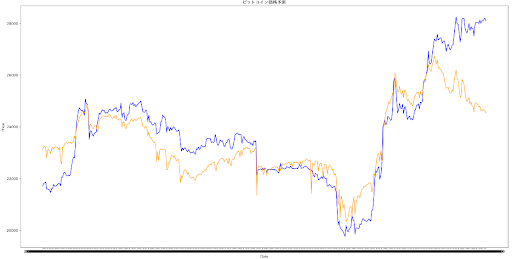
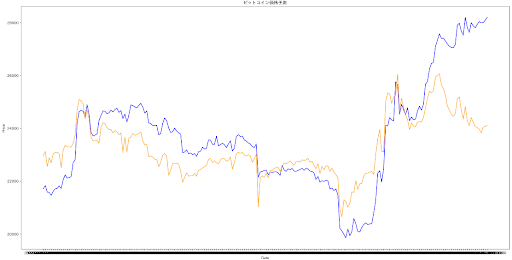
試しに特徴量を減らしてみた結果が下図。左が1h足(特徴量:取引量)、右が2h足(特徴量:取引量、2h足MAと価格との乖離)
結果がさらに悪化したため、逆にMAの特徴量が大事なことに気付く。
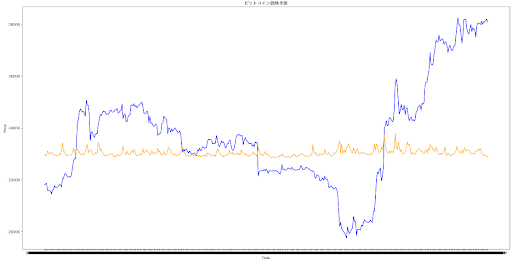
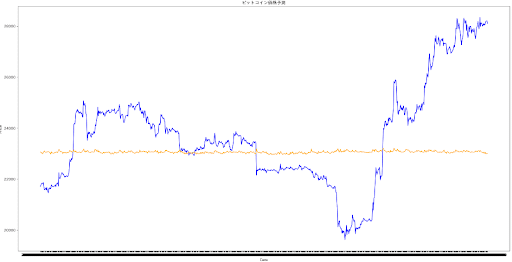
特徴量を1h足25MA, 75MA, 200MAに加え、4h足25MA, 75MA, 200MAの計6本と取引量に変更して、これまでで一番良い結果が得られた。
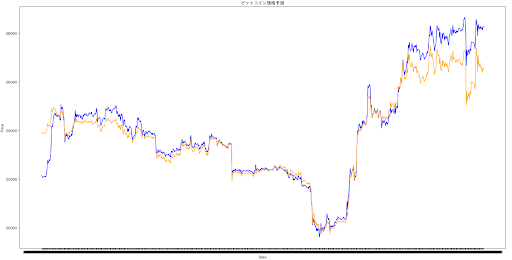

このモデルはここが限界と判断。
895時間のデータで予測するのに1時間足を使用して精度が高めな条件が分かったが、冒頭で示した最初の結果と大した差はない。今回の収穫はMAの特徴量が大事であることがわかったくらい。
結果を以下にまとめた。
| 間隔 | 評価時間 | 特徴量 | loss | 平均 | RSD(%) |
| 1min | 895h | 5分足25,75,200MAと価格の乖離、取引量 | 0.050, 0.002, 0.009, 0.080, 0.126 | 0.053 | 86.1 |
| 1h | 895h | 1h足25,75,200MAと価格の乖離、取引量 | 0.03, 0.0, 0.01, 0.02, 0.05 | 0.023 | 71.9 |
| 2h(1時間足1つ飛ばし) | 895h | 1h25,75,200MAと価格の乖離、取引量 | 0.03, 0.0, 0.01, 0.06, 0.1 | 0.028 | 71.2 |
| 2h | 895h | 取引量 | 0.03, 0.0, 0.03, 0.08, 0.24 | 0.077 | 108.9 |
| 4h(1時間足3つ飛ばし) | 895h | 1h足25,75,200MAと価格の乖離、取引量 | 0.03, 0.0, 0.01, 0.06, 0.1 | 0.041 | 86.7 |
| 4h | 895h | 4時間足25,75,200MAと価格の乖離、取引量 | 0.02, 0.0, 0.01, 0.03, 0.02 | 0.016 | 62.6 |
| 1h | 895h | 取引量 | 0.02, 0.0, 0.03, 0.07, 0.22 | 0.069 | 117.9 |
| 別日検証 | loss | 平均 | RSD(%) | ||
| 4h | 895h | 4h25,75,200MAと価格の乖離、取引量 | 0.01, 0.0, 0.03, 0.03, 0.04 | 0.023 | 71 |
| 1h | 895h | 1h25,75,200MAと価格の乖離、取引量 | 0.0, 0.01, 0.04, 0.04, 0.1 | 0.036 | 92.5 |
| 1h | 895h | 1h25,75,200MAと価格の乖離、 4h25,75,200MAと価格の乖離、取引量 | 0.01, 0.0, 0.02, 0.01, 0.02 | 0.012 | 54.3 |
| 1h | 895h | 1h25,75,200MAと価格の乖離、 4h25,75,200MAと価格の乖離 | 0.01, 0.0, 0.02, 0.03, 0.02 | 0.015 | 71.1 |
一番良かったモデルを用いて、未来のビットコイン価格(モデル作成に使用しなかったデータ)を予測しようと考え、モデル作成に使用しないデータを20時間分足した。(図の緑部分)
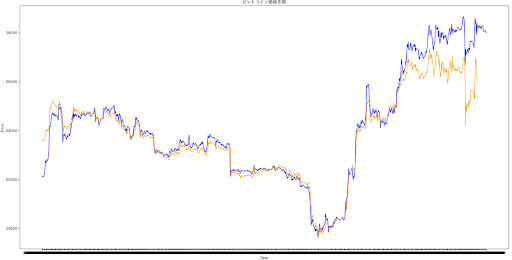
が、よくよく考えたら、これまで使用していた特徴量では未来の価格を予測できないことに気付く。今得られる特徴量を使って、今の価格を予測していたにすぎなかった。
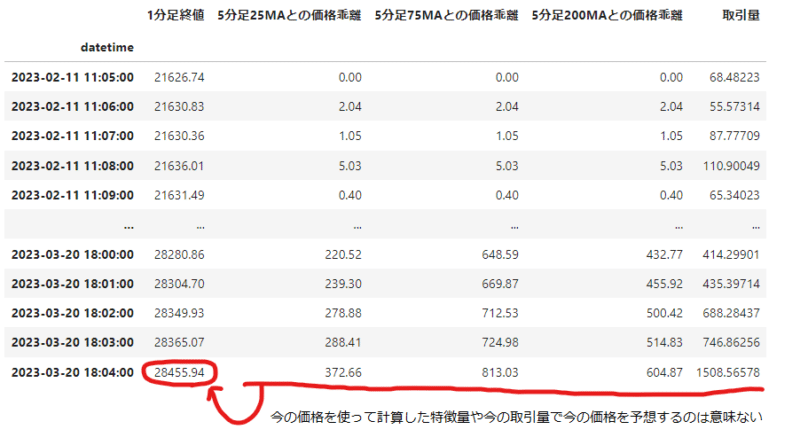
ということで、特徴量を1時間ずらして、1時間前のデータを使って今の価格を予測できるようにデータフレームを変更。
予測ロジックも再確認。↓
- 1時間前までの過去のビットコイン価格データを使って予測モデルを作る
- 新しい一時間足が確定したら終値と、それにより新たに計算できる特徴量を取得する
- 2を使用して1時間先のビットコイン価格を予測する
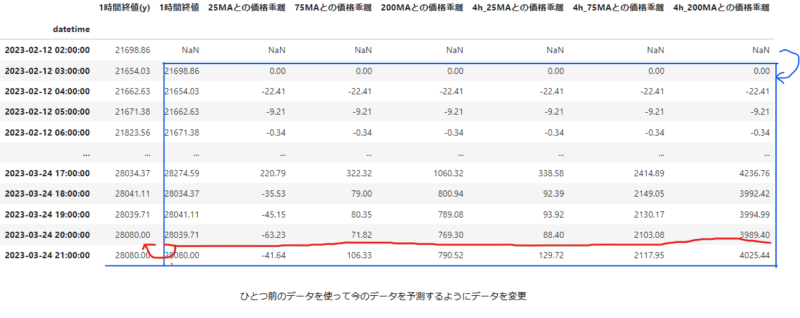
また、移動平均の値が前のデータを使用することから、データフレームの最初の方が値がおかしくなっていることに気付いた。そのため最初の100行を削除、その分取得データを増やすことにした。
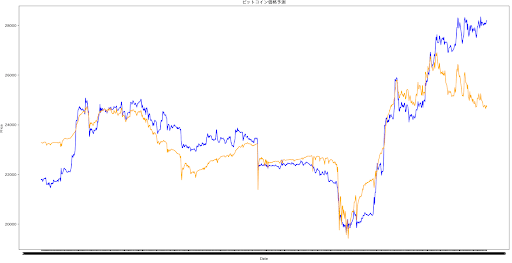
このデータフレームを使用して新たに予測した。結果が以下の通り。このレンジでは予測が当たってるように見えるが、1時間前のデータを学習に与えているわけだから、当たるのは当然。
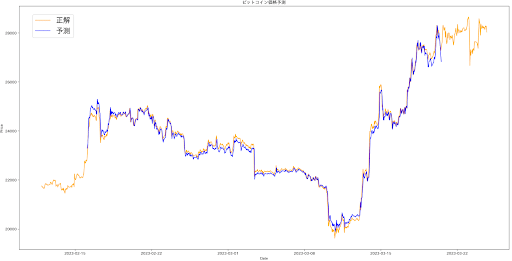
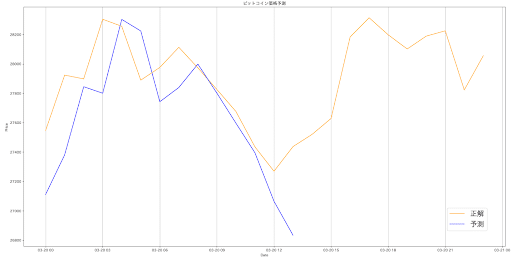
拡大して、予測ができているのかを確認。(下図)
1本先を予測したいのに、予測は見事外れている。
与えられた正解を追いかけるように価格が上下しているだけのように見える。1時間ずれが生じている、いわゆるラグモデル。1時間後の価格が上がるか下がるかを予測するには使えない。
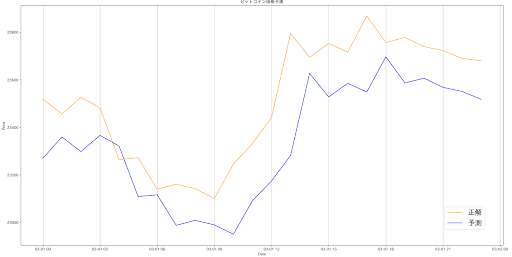
価格を抜いて、MAのみを特徴量にしたが、結果は同様。モデルを大きく変える必要がありそう
次の検討項目
検討内容は下記。優先順
- モデル評価の方法確立:今回のモデルがダメだったのはわかったが、これを数値化する。上昇したかどうかの2択で、正解率を出すなど
- input_shape値の選択:重要なパラメーター。まずはデータの変形など、変更のための手順を確認
- 特徴量の選択:MACD,RSI,ボリンジャーバンドなどのオシレーター指標を特徴量に加えて変化を見る。
次の検討に進むと同時に、時系列分析の基礎知識も身に着けるべきと思う。これが一番の近道だったりする。ブログを見ていると、ラグモデルになっている結果をよく見かける。
コメント