2023/03/22
ニューラルネットワーク(RNN,LSTM)、ロジスティック回帰分析を基本ロジックとし、勝率60~70%の自動トレードを目指す備忘録。
裁量トレードができるのがベストだけど、再現性が低い。安定した収益を上げれる方法として自動売買を考えた。発端は以下のアイデア。これをコードに落とし込んでいく。
今週の作業 LSTMモデル構築
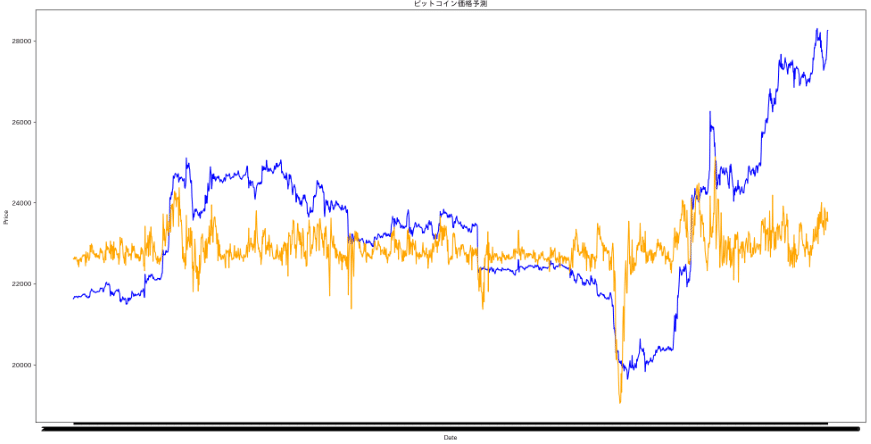
23/3/22 ChatGPTにコードを教わりながら、LSTMモデルを初めて構築し、約600時間のビットコイン価格を1分間隔で取得した。データを5分割し、5通りの訓練データ、テストデータでバリデーションを行い、モデルを構築。モデル構築に用いた全期間のビットコインの値と予測の値をプロットして予測精度を確認した。
データ前処理
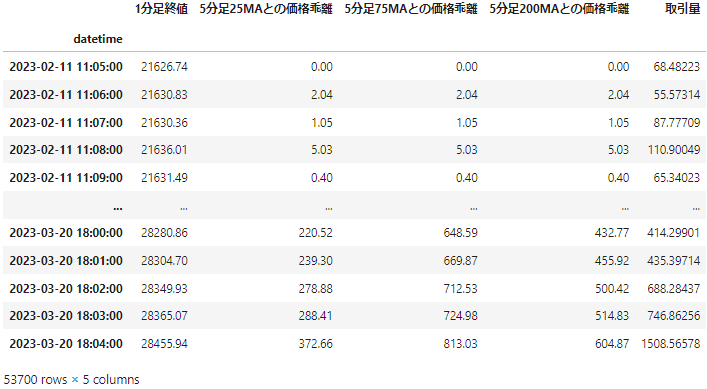
BinanceAPIを使用して価格を取得。2023-2-11 – 2023-3-20の期間で、1分足終値を予測対象とした。ほかに重要そうな値4つを特徴量にするべく、データフレームにそれぞれ格納した。
結果
Youtube動画とChatGPTを参考に、すすめられるままにハイパーパラメーターを設定。
1分おきに取得したデータ53700を5分割し、5通りの訓練データ、テストデータでバリデーションを行い、モデルを構築。
慣れないnumpy配列が難しい。指定のデータ型で引数に渡す必要があり、エラー連発でかなり時間かかった。

5回の平均とRSDを算出。lossの値は思ったより小さい。(平均0.053, RSD86%)
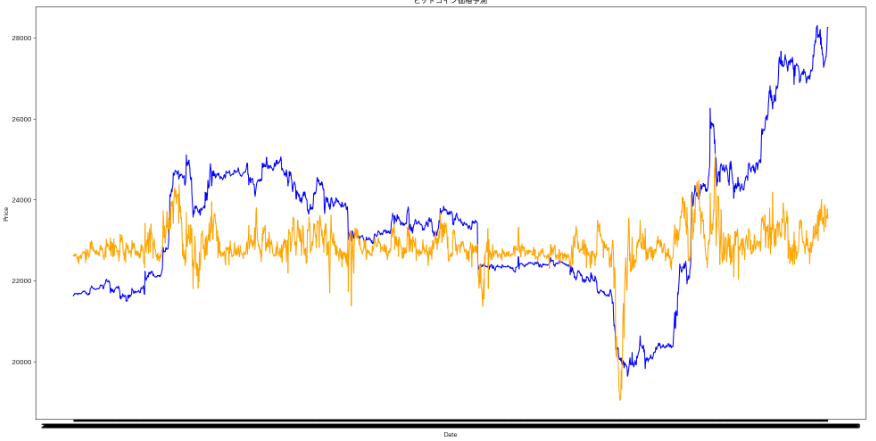
使用した全期間のデータを実際の価格と、モデルで予測した予測値をプロット。
予測は全然ダメ。特徴量は5分足の移動平均線との乖離率、25MA,75MA,200MAの3本と、取引量(計4つ)
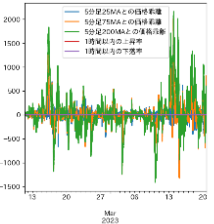

使用した特徴量(上昇率、下落率除く)影響あるかはわからない
ハイパーパラメーターの設定(pythonコード抜粋)
# LSTMモデルの構築
def create_lstm_model(n_features):
model = Sequential()
model.add(LSTM(50, activation=’relu’, input_shape=(1, n_features)))
model.add(Dense(1))
model.compile(optimizer=’adam’, loss=’mse’)
return model
model = create_lstm_model(n_features)
history = model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0)
loss= model.evaluate(X_test, y_test, verbose=0)
考察、学び
・データを正規化(平均0、分散1のデータに変形)して予測→元に戻すの手順で、未知データを予測するであってる?
・1分間隔でとってるから、縦軸のレンジが反映されないのはいい気もする。長期の予測はトレード効率が悪いけれども、せっかく取得したデータなので、次は予測期間が長いままで、データのサンプリング間隔を広げてみる。(1時間ごとなど。)
・予測に使う訓練データのinput_shapeは大事な値と思われる。今回は(1, 4)
Youtubeではinput_shape=(30, 1) としていた。(https://www.youtube.com/watch?v=y-XvMZq33c4&t=2007s )
input_shapeの2番目の引数は特徴量だから関係なし。第一引数をいじってみるべきと思う。
理想は時間的な区切りで区切るべき。株価では1日、仮想通貨でもこれは理想。スキャルピングくらいの短期トレードが理想なので、ここの数値をどうするかは重要と思う。
以下、input_shapeの説明
input_shapeの2つの引数の意味は、(1, n_features)という形状を指定しているため、以下のようになります。※第一引数:1、第二引数:n_features (今回設定した値)
- 1: タイムステップの数を表します。LSTMモデルでは、時間的な依存関係を扱うことができます。1つのタイムステップには、1つのデータポイントが含まれます。
- n_features: 特徴量の数を表します。ここでは、1つのタイムステップでn_featuresの特徴量を持つデータを扱うため、n_featuresを指定しています。
タイムステップとは、時間的な依存関係を表すためのデータの区切りのことです。例えば、株価予測の場合、1つのタイムステップは1日のデータに対応します。タイムステップの数が増えるほど、モデルはより多くの時間的なパターンを学習できますが、同時に計算コストも増加します。特徴量は、各タイムステップにおいて観測されるデータの種類を表します。例えば、株価予測の場合、特徴量には始値、高値、安値、終値などが含まれます。
タイムステップ数の区切りに意味的な区切りがある場合、それを採用することが一般的です。例えば、株価予測の場合、1日が区切りとされているのは、株価が1日ごとに取引されることによって価格変動が生じるためです。
ただし、意味的な区切りがない場合でも、適切な区切りを見つけることができます。例えば、センサーデータの場合、1分ごとにデータが取得されることがあるが、それぞれのデータポイントは連続しているため、時間軸での区切りを設けることができます。
重要なのは、適切な区切りを見つけ、データを正しく扱い、意味のある予測を行うことです。
次の検討項目
・同じ時間軸で、サンプリング数を1時間に1回にする。(今回は1分に1回)
・input_shape値を変える。1時間足であれば区切りとして1日。
コメント